I primarly wrote this to test .md formatting on this website.
Transformer architecture was first introduced in the now famous "Attention Is All You Need" paper in 2017. The main goal of transformer is to model long-range dependencies in sequences through parallelization of matrix operations.
Before transformer, the field of processing and generating text by Neural nets relied on processing tokens sequentially: . For sequence e.g. "Car has four wheels.", when processing the token "four", is its embedding vector, and is a latent representation summarizing the "Car has". (e.g. an LSTM cell) integrates the new input with prior hidden state to produce , a (compressed) representation of "Car has four". The obvious problem is than each token is processed sequentially (token 1 -> token 2 -> token 3....), which heavily restricts the computation. Another, major issue, which I will jsut mention and not explain to detail, is the problem with vanishing/exploding gradients during training and context loss over long sequences - at each time step the entire previous representation is compressed into a fixed size vector ...
As mentioned, transformer architecture eliminates recurrence and instead computes relationships between all tokens in parallel using process called self attention. But let's start from begging.
Input
The input to an transformer is a sequence of tokens ( is the seq. length and is the embedding dimension). The model treats input as a set not an ordered sequence - permutation-invariant, thus it uses Positional Encoding using sinusoidal functions to inject order of tokens in sequence:
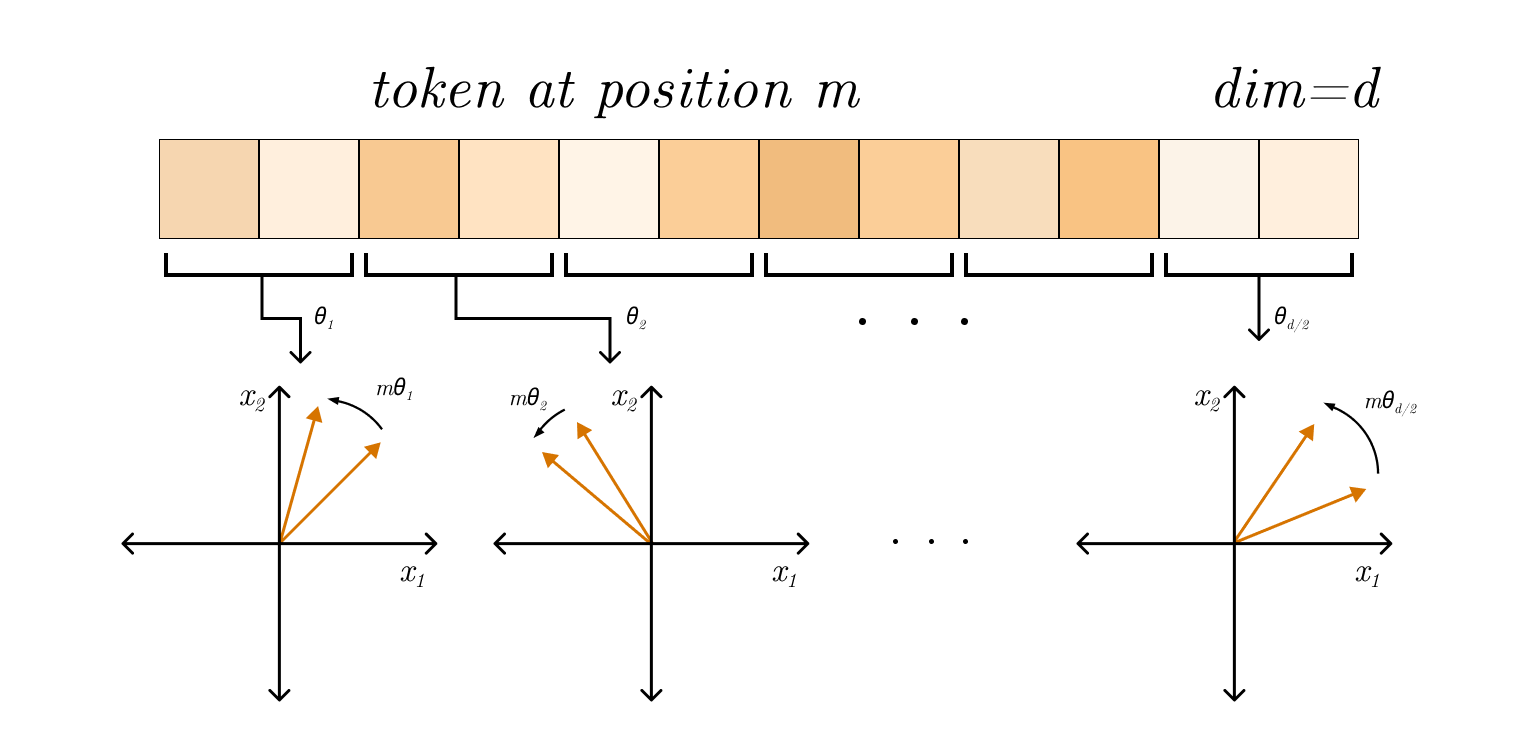
In other terms, instead of attaching indices tokens, the transformer gets a unique vector in . Using sinusoidal encoding also implies that: for some linear transformation enabling the model to infer relative distances. Last but not least, the fact that the pos. encodings are deterministic and not learned helps generalize the model.
is projected into spaces:
Attention
At high level, attention allows each token to look at all other tokens, score their relevance and builds a weighted combination.
Let's lay it out on the table, the main (famous) equation of scaled dot-product attention:
Looking at this attention equation, the numerator: where each tells us how well token matches token in the learned representation space. In higher level terms, larger means that token is more relevant to token and vice versa. The is introduced to stabilize training as products grow with which could push gradients near zero (softmax saturation).
The softmax function where in its general form: where and computes each component of . For our attention case, this means: This guarantees that and each row therefore shows how token distributes its attention across the entire input sequence. This builds a matrix , where each row is a probability distribution over tokens, thus: is a contextual embedding of token . Instead of utilizing just single attention for the entire sequence, the model learns several token2token pairs at once in parallel using Multi Head Attention:
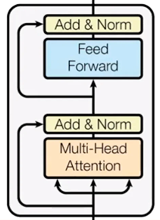
Transformer Block
A full transformer layer consist of:
Encoder & Decoder
As visible on the full architecture above, transformer is divided into Encoder and Decoder sections. The encoder produces a set of contextual representations . The decoder than generates the output autoregressively: is conditioned on prev. generated and encoded input . A mechanism called CrossAttention(Q,K,V) enables it, where comes from decoder states and come from encoder output . I asked LLM on this to produced an analogy, and it generated quite an intuitive one:
Encoder is like a court that builds a complete, structured case file from all evidence; decoder is a lawyer writing the final argument, repeatedly checking that case file to pick the most relevant facts while composing each sentence. (Unspecified AI, 2026)
Code
The following code is an implementation of transformer architecture from scratch in NumPy.